Fun with AWS Lambda, illustrated by cats
Recently, we got to experiment with AWS Lambda, which I’d heard a lot about but hadn’t used before. Having a concrete use case and getting hands-on with the setup has really improved my understanding of what Lambda does, and helped me think about other ways we might use it, so I wanted to share an overview of what we’ve been doing. I’ll be talking about the technologies we used, but not getting into actual code. I’ll finish by talking about how it went and what changes we might make in future.
The problem
We’re building an app that’s going to be used by our client’s employees to give them direct access to tailored work-related information. To do this, we need to access a load of data from the client's systems. They've never had to share their data with anyone before, so they didn't have any integrations set up.
Very early on, we started discussions about getting APIs set up, but because of the way the data was stored – in legacy systems and with third-party dependences – this wasn't going to be easy, quick or cheap. We needed to start testing the product far earlier than the APIs were going to be available, which led to a great opportunity to experiment with AWS Lambda.
Stage 1 - fun with data entry!

Early on, we got data via email in a load of non-standardised spreadsheets. We printed them out and typed the data into our very clunky early-stage admin system. It wasn’t pretty and it wasn’t very efficient, but it did let us kickstart our MVP app with enough data and functionality to start testing with users very quickly.
Stage 2 - fun with CSVs!

To help us speed up the process and as part of preparations for the next stage of data exchange, the client arranged to export the data into standardised CSV format, which they sent to us via Dropbox. We built functionality in our admin system to import and parse the files. This saved us a great deal of time and allowed us to scale up from our initial dozen or so users to the low hundreds, but still required human intervention so wasn't fully scalable.
Stage 3 - fun with Lambda!

We worked with the client to find a way to deliver the CSV files that would allow us to fully automate the import process. They initially suggested setting up an SFTP server, but since all our infrastructure was hosted in AWS, using ECS, we agreed on S3. S3 also provided us with easy to use encryption at rest, enabling controllable secure storage of the data. We chose to use Lambda in the import process because, in combination with S3, it gave us the triggering for free. We could have built this functionality ourselves by writing a task that would continuously poll the S3 buckets for new files, but this would have introduced unnecessary complexity to our system. We preferred to push the complexity to AWS; we set up monitoring so we could ensure things were running smoothly, but essentially treated it as trusted functionality.
The Lambda setup itself is pretty simple. The Lambda function is triggered directly from the S3 bucket whenever a new file is created. We did some research into whether we should insert SNS and SQS into the setup, but found that our use case was simple enough to do without them for now. If we want to enable retries or other more complex behaviour in future, this might be something we look into again.
The Lambda function itself does only one thing: it starts an ECS task, passing in the filename from the trigger. All the import logic, interaction with our database and error logging is done by the Elixir code this task runs. This separation was deliberate; we wanted to have all import functionality in our codebase for clarity and so we could reuse it in the UI, retaining the manual functionality for flexibility. Making the Lambda function responsible only for extracting the filename and starting the task keeps our execution time short, which keeps costs low and ensures we aren't in danger of hitting any of the Lambda limits.
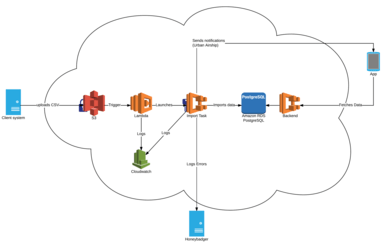
After initial experimentation using the AWS console, we used Terraform to build all the infrastructure. The bit we found most tricksy was getting all the user policies right, so that every user and piece of infrastructure could access what they needed, but nothing more. Here's a list of all the resources we needed for a single data integration (with Terraform resource names):
- Bucket to keep the data in (aws_s3_bucket)
- Key to encrypt the data with (aws_kms_key)
- User to allow the client to write to the bucket (aws_iam_user)
- Access key to allow the client to log in as the user (aws_iam_access_key)
- Bucket policy to allow only the client's user to upload files (aws_s3_bucket_policy)
- User policy to allow the client's user to upload and encrypt files (aws_s3_bucket_policy)
- Task to run the data import (aws_ecs_task_definition)
- Role for the task to run as (aws_iam_role)
- Policy to allow the data import task to read from the bucket and decrypt the files (aws_iam_policy)
- Attach the policy to the task role (aws_iam_policy_attachment)
- Lambda function (aws_lambda_function)
- Zipped up lambda code for the Lambda function to run (archive_file)
- Role for the Lambda function to run as (aws_iam_role)
- Policy to allow the Lambda function to run the import task and write logs (aws_iam_policy)
- Attach the policy to the lambda role (aws_iam_policy_attachment)
- Notification to invoke the Lambda function when a file is uploaded to the S3 bucket (aws_s3_bucket_notification)
- Cloudwatch log group for Lambda logs (aws_cloudwatch_log_group)

How did it go?
We've had this setup running for a couple of months now, initially with a single data import, and more recently with an additional three. We've had relatively few problems and it's supported us to scale up our user base considerably. Initially we saw a few errors caused by edge cases we hadn't allowed for in the importer, but we were alerted to these by Honeybadger, and were able to diagnose and fix them using the Cloudwatch logs. A slightly more serious issue happened when applying a Terraform config unexpectedly recreated one of the IAM users that uploads the files. Since this changed the keys, the client uploads started to fail and since this isn't something that was being monitored at either end, we didn't catch it straightaway. We're working with the client to set up alerts on their side if the uploads fail so we'll catch issues like this more quickly in future.

We're still hoping to get API integrations running for this project at some point in the future. This would give us a number of advantages over the Lambda setup: we’d be able to have near real-time data, and with a two-way integration we’d be able to write back to the client so we could maintain a single source of truth. For the time being though, we're finding that the Lambda setup is working really well for us.
If you have any questions or comments, just reach out to us @madebymany.
Continue reading
Business Strategy
The Empathic Consultant
How we balance people, business and power in our work as product designers

Process
How to waste your customer’s time as well as your own
Quality customer research is the foundation to creating things people want to use — and potentially love to use. But it’s really easy to mess up this kind...

People
Building a Human Company
On the cusp of our 10th year, Made by Many is more human than ever. A wonderful collection of misfits, eccentrics and oddballs is what makes us the compan...