Seven unbelievable hacks to make your site fly (Jeff Bezos hates this trick)

Everyone hates waiting. There’s been a fair bit of research suggesting that even a tiny increase in waiting for a page to load could reduce the number of pages someone would bother viewing. Speed has become a considerable focus for engineering teams within high circulation publications such as the Guardian and FT. It’s particularly critical for transactional sites like Amazon and has been proven to have an effect on sales.
When you click a link, lots of stuff happens; there are many factors that affect how quickly you can start reading and interacting with the page.
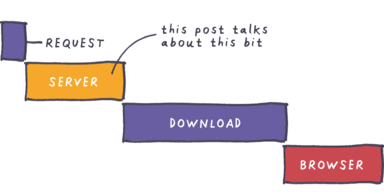
- Browser makes a network request
- Server decides how to respond and generates a response
- Server begins transmitting response over the network
- Page appears in the browser to be parsed and (DOM) rendered etc.
One way to speed up the server-side of things is to implement some sort of caching strategy. This post outlines a nascent understanding — developed while doing just that for one of our client’s sites. The resulting response-time displays a bit of a drop-off, reminiscent of the UK’s post-Brexit economic prospects.
The intention is to improve some of the following:
- Make pages load more quickly 💨
- ...by doing less stuff 😴
- ...so that it takes less time to serve a page, and more pages can be served (to more users) with a given infrastructure
- It should also make the site robust against sudden spikes in traffic 💪, a risk that comes with interwebs success!
TL;DR
Processing effort can be reduced by caching pages that have already been rendered for as long as they’ve not changed. When a page does have to be re-rendered, any bits of it that haven’t changed can be reused. The tricky part is balancing simplicity and speed with a comprehensive un-caching strategy for content that has been updated.
What even is caching?
Picture this: it’s lunchtime and you go to the sushi shop. They have popular items on display in boxes in the fridgey thing. But wait! You’re a vegetarian or something; they don’t have anything that doesn’t have fish 😰! It’s okay — they still make you stuff if you ask for it, it just takes a little longer 😴. The other people in the queue don’t mind too much, they can still be served quickly. Well that’s caching, kinda.
The idea is to prefer doing stuff that is quick and to only do stuff that takes longer when necessary.
Stuff that takes quite a while:
- Messing about with data, finding it, joining it together etc
- Putting it into pages by rendering out HTML
Stuff that doesn’t take that long:
- Retrieving a saved version and bunging back a load of flat text
- Discovering that there is no saved version
Investigation
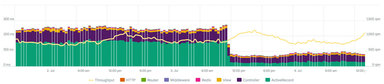
Before starting anything like this, it’s worth setting a baseline against which to compare results. I started by putting an Application Performance Monitoring tool (APM) on the production site. I used ScoutApp. Soon I had some nice graphs to look at, revealing which parts of the site would benefit the most from some tuning up.
There are generally about 1,000+ people on the site at one time reading the journalistic content, which is published regularly and shared quite a bit on social media. Based on the traffic and commensurate CPU time, I decided to focus on the articles listing page, the articles themselves and the homepage.
Outta the box
The site runs on a number of servers, behind a load balancer, a CDN, and NGINX, which has a smidge of proxy caching. The NGINX cache holds onto pages for 10 seconds, and Akamai (the CDN) for seven seconds. This means that very frequently visited pages will load super quickly. Because while some requests will go through to the app server, further requests to the same content within the next 10 seconds will be sent the page that was rendered for the previous requester. If demand for a page is high-ish, but not quite that high, then all this is of no use to us 😭. It does, however, take the edge off very high frequency spikes of traffic.
Y can’t U make it for longer?

What about keeping stuff in the cache for a bit longer? To increase the likelihood that a page will be served out of the cache. The longer that rendered pages are saved for, the fewer requests need to go all the way to the app server to be arduously generated. However, if the content does change, the site would still be showing the old version.
Invalidation vs deterministic keys
So when a page (or some data that lives on it) changes, we need to get rid of the saved version and make another. How?
- Wait for it to expire?
This could be long, and comes at the cost of publishing immediacy - Find and delete the saved version when making new updates
This is more imperative and could be difficult to synchronize
Or
The page is saved with a key that reflects its state, importantly it would include the timestamp of the last update. If the page changes, its key changes. Each time a page is requested, a lightweight database query can check to see when the page was last updated. If there exists a key for that timestamp, then the cached version can be returned. If not, the page is re-rendered and saved against the new timestamp. The cool thing about this is that old keys can just be left to expire.
Composition and association
When composing the keys for pages, it’s important to ensure that they are reflective of everything on the page that could update–necessitating a re-render. For example: a listing page lists a number of objects, possibly of different content types. In this case an aggregated key is composed, including a timestamp from each item that appears on the page. If any item within that collection is updated, the composite key for that listing would be superseded by a new one and the page would have to be regenerated.
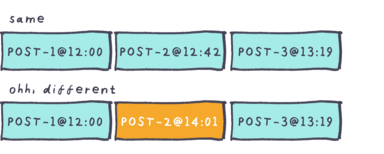
Sometimes a piece of content belongs to another type of item, for example a comment on a post. These relationships can be configured such that when a child item is modified, a message is sent to the parent, telling it to update its timestamp as well. Doing this for associated content types reduces the complexity of generating and validating keys.

Fragment caching
When a page is re-rendered, it’s quite likely that not everything on it needs to change each time. So each data-driven element on the page can be cached as a page fragment with its own key. The key describes the placement, the content and its state. This way, when a page has to re-render, only the bits that changed need to be rebuilt. With a careful key naming strategy, these fragments can exist within other fragments, cascading invalidation to their parents when necessary. This is called “Russian doll caching”
Sometimes when an element needs to fetch additional (related) data from the database, the query can be initiated from inside a template. If the template is cached (and therefore doesn’t get parsed) then these queries are avoided.
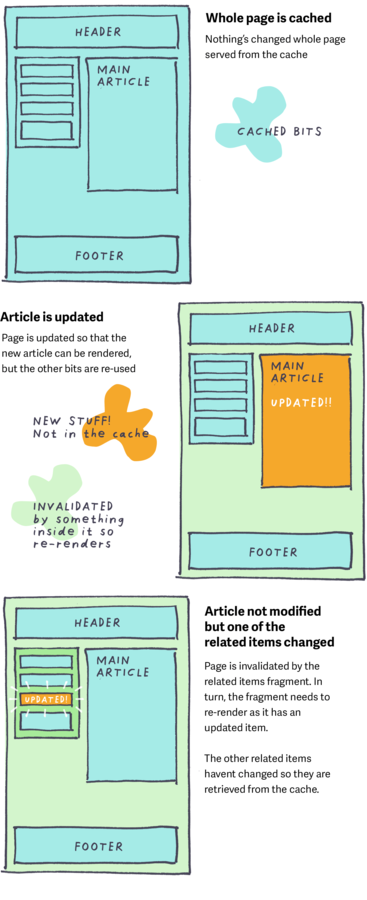
Expensive or frequently changing site-wide elements
Often it isn’t as simple as having only a couple of data-driven objects on a page. In this project the site has a meganav, which highlights a few different types of recently published content.
Rendering the meganav on every page not only creates a database and rendering overhead–it also increases the specificity of the cache key required to reflect the objects on each page. The high number of items comprising the key heightens the risk of key invalidation, as there are more timestamps which could potentially change.
One solution could be to render and save the content pages without the meganav. Then to load it in asynchronously after the page has loaded. This has the benefits that:
- It can be rendered once and shared.
- Cached pages are not invalidated by changes to the meganav.
- Page size gets a little bit smaller.
- It can even use browser caching to limit its impact on network overhead for subsequent page visits.
- Asynchronous loading is barely perceptible as the meganav requires an interaction to activate.

Impact
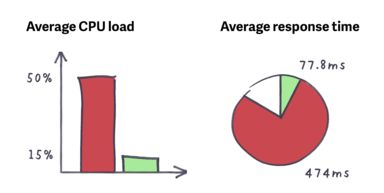
While the real impact here should be reflected by user experience, here are a couple of observations from the AWS console. The homepage was the biggest loser, going from an average response time of a couple of seconds to < 100ms. In fact the average across the traffic to the whole site (including non optimised sections) went from 474 ms, to 77.8 ms. The average CPU use of the servers dropped from 50% to 15%, and even the database is having a better time now!
What's next?
The optimisations discussed here are very much focused towards getting the servers to respond quickly. This has improved infrastructure utilization and to some degree, user experience. There are of course many more front-end opportunities to be explored that could offer particular value to users, aimed at making content readable on screen as quickly as possible. This is especially worthwhile for users of cellular networks.
Some closing thoughts
- Time is expensive
- Servers are relatively cheap
- ...so the benefit must be felt by the user.
- ...Although scaling horizontally can’t be done indefinitely as other bottlenecks will introduce themselves, e.g. multiple web servers could overload the database.
- No solution is perfect, there are tradeoffs to be considered.
- Application/infrastructure complexity can affect productivity, maintainability and the number of possible failure modes.
- Stuff gets stuck in caches and it can be difficult to debug. Caching is great and should be considered from the get-go. But beware of premature optimisations!
- Poorly conceived load testing can be an expensive way to test the wrong thing. It’s important to consider the spread of real live traffic. Any simulation is just that, but anything that gives you more insight is probably worth doing.
- Redis. If you learn nothing else from this, set a fucking expiry. Otherwise everything goes axsplode.
Continue reading

People
Introducing the Made by Many professional development programme
Made by Many has been practising digital product development for ten years (and more if you count our combined experience at previous companies). A common...

Technology
What if AI is a failed dream?

Design
What we mean when we talk about ‘Product Feels’
‘Product Feels’ grab people by the heart and make them feel something every time they use a product.